Urban Analytics Lab
A research group at the National University of Singapore

About us
We are introducing innovative methods, datasets, and software to derive new insights in cities and advance data-driven urban planning, digital twins, and geospatial technologies in establishing and managing the smart cities of tomorrow. Converging multidisciplinary approaches inspired by recent advancements in computer science, geomatics and urban data science, and influenced by crowdsourcing and open science, we conceive cutting-edge techniques for urban sensing and analytics at the city-scale. Watch the video above or read more here.
Established and directed by Filip Biljecki, we are proudly based at the Department of Architecture at the College of Design and Engineering of the National University of Singapore, a leading global university centered in the heart of Southeast Asia. We are also affiliated with the Department of Real Estate at the NUS Business School.
News
Updates from our group
Feel free to follow us on LinkedIn and through our RSS feed.






People
We are an ensemble of scholars from diverse disciplines and countries, driving forward our shared research goal of making cities smarter and more data-driven. Since 2019, we have been fortunate to collaborate with many talented alumni, whose invaluable contributions have shaped and enriched our research group, and set the scene for future developments. The full list of our members is available here.
Filip Biljecki
Assistant Professor
Matias Quintana
Research Fellow
Edgardo G. Macatulad
PhD Researcher
Koichi Ito
PhD Researcher
Zicheng Fan
PhD Researcher
Xiucheng Liang
PhD Researcher
Sijie Yang
PhD Researcher
Youlong Gu
Research Engineer
Kun Zhou
Research Assistant
Weipeng Deng
Visiting Scholar
Jussi Torkko
Visiting Scholar
Maxim Shamovich
Visiting Scholar
Recent publications
Full list of publications is here.
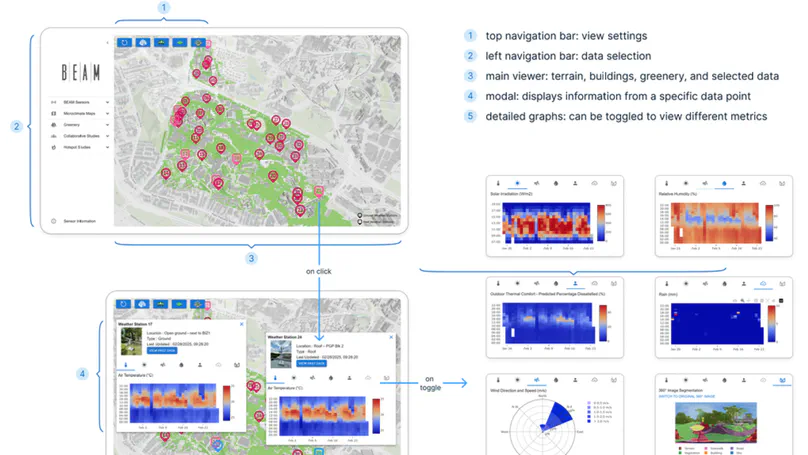
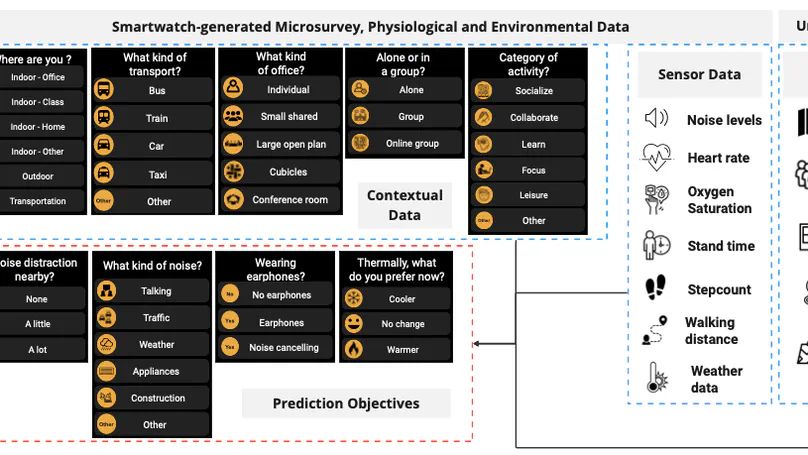
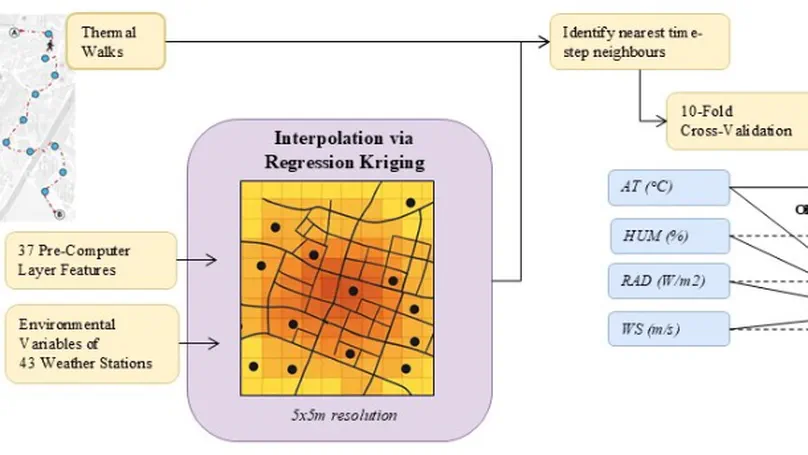

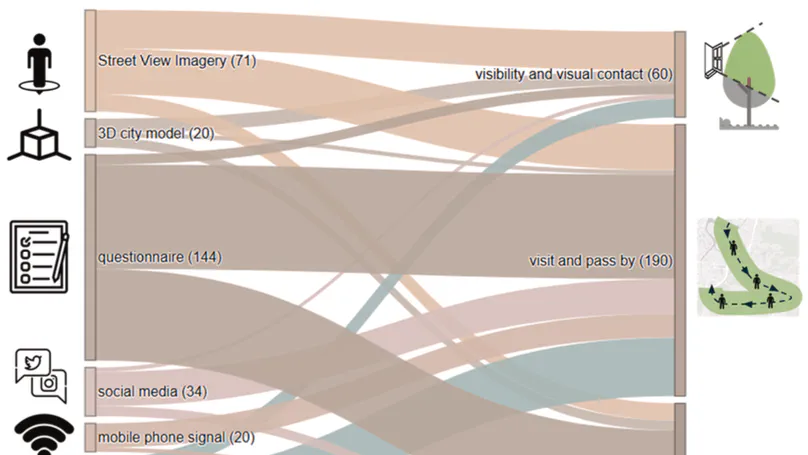
Contact
- [email protected]
- SDE4, NUS College of Design and Engineering, 8 Architecture Dr, Singapore, Singapore 117564
- X